
Written by: Emily Cartwright
Edited by: Ellen Osborn
As graduate students, we are taught to think critically about scientific publications, but how prepared are we to spot images that are not what they seem? Scientific data takes on many forms and is presented in graphs, photographs and tables in a finished publication, creating a complex task for those synthesizing and interpreting the results of studies. Images often make up a sizable proportion of this data and can easily be taken at face value; after all, it is an image of something real, right? This has often been my attitude towards images in papers. However, recent work primarily headed up by Elisabeth Bik, has brought to light just how common image manipulation is in scientific publishing.
Elisabeth Bik, a scientist who worked at Stanford University for over a decade, conducts studies on image duplications, a specific type of image manipulation, and brings attention to this issue on her Twitter account. Bik posts images that she suspects have been manipulated on Twitter and often asks others to see if they can spot the duplications that she has found, in a slightly dark game of “I Spy”. Her posts help bring attention to what is becoming an important issue, as both intentional and unintentional image duplications are not uncommon in scientific publishing. A study by Bik, et al. 2016 found approximately 4% of all biomedical publications (sampled across 40 journals) contain some form of image duplication in them, either with unintentional or intentional manipulation, and in a more generalized, self-reported study, roughly 2% of scientists admitted to manipulating data in their work (Fanelli, 2009).
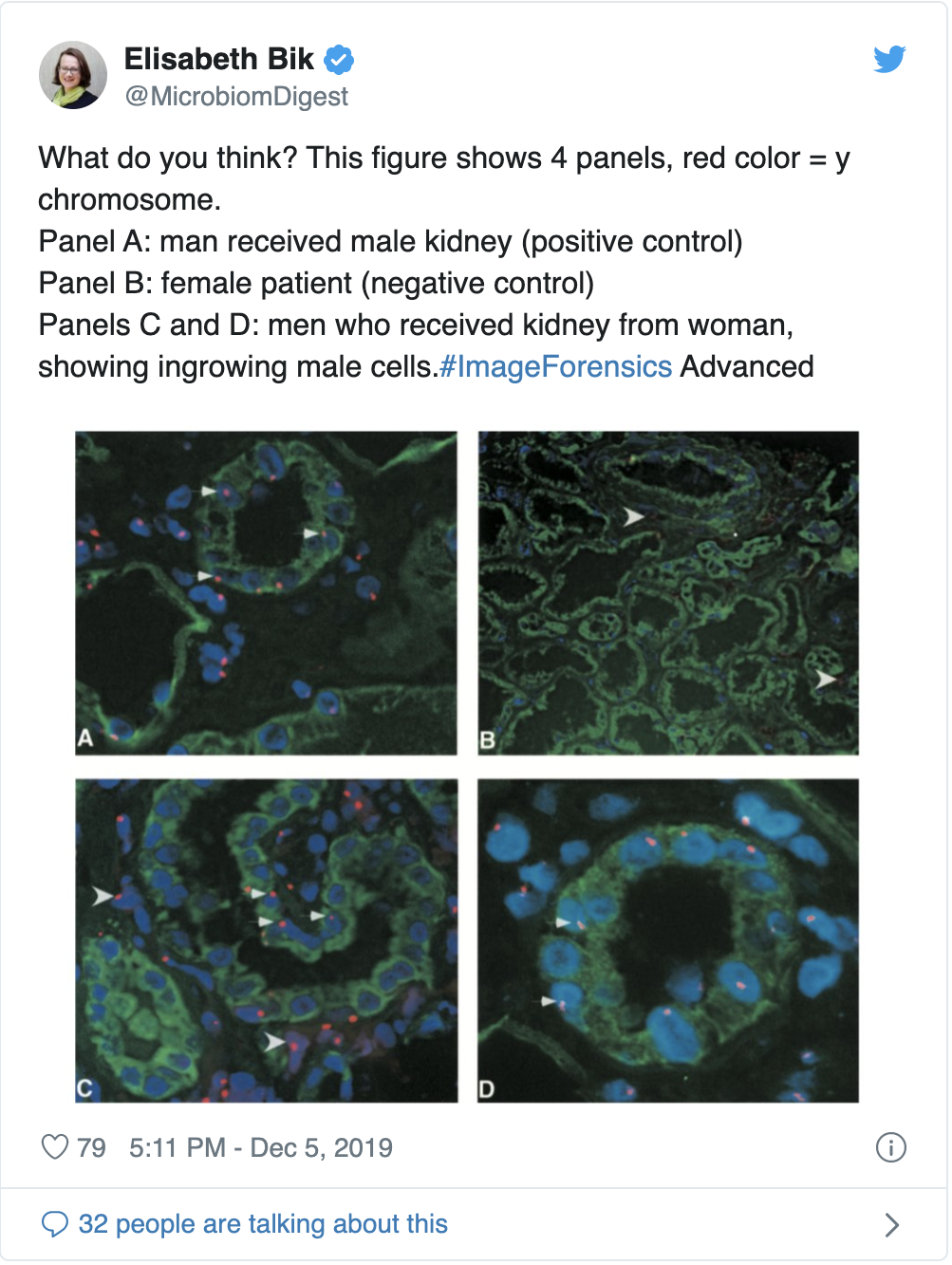
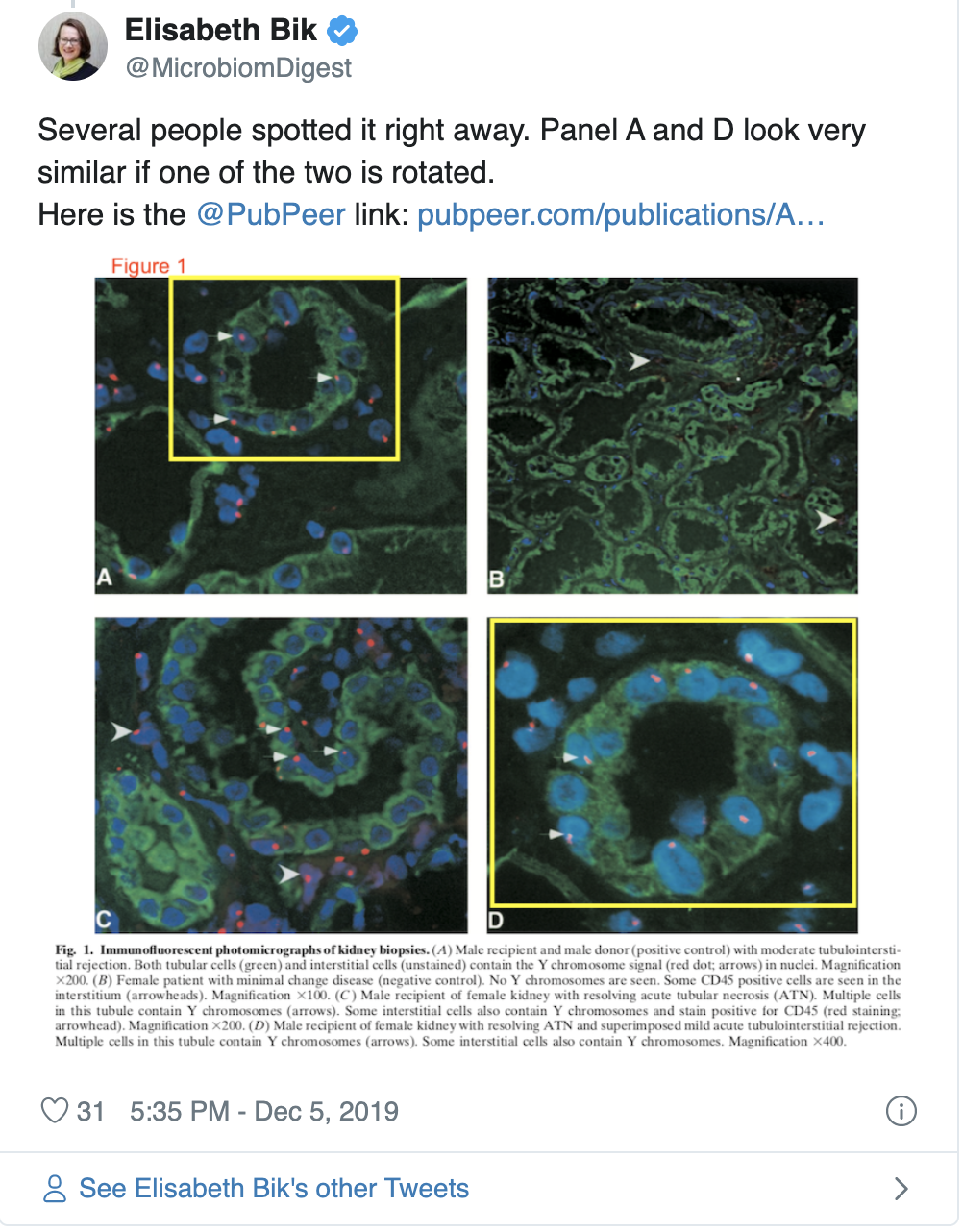
An intensive study published by Fanelli, et al. in 2019 rigorously tested if several parameters contributed to whether or not papers were more likely to contain duplicated images. The study sampled over 8,000 papers published by PLOS One between 2014-2015 and tested if pressure to publish, peer-review, implementing misconduct policies, or gender had any effect on the likelihood of papers to contain manipulated images. The study identified that social control (the level oversight placed on researchers by academic institutions, peers, etc.), cash-based incentives, and whether countries had legal policies in place for image falsifications in academic publishing all contributed to whether image manipulations were likely to occur. In contrast, the author’s gender did not play a role in whether papers were more likely to contain manipulated images. It is important to note that despite image manipulations occurring in noticeable numbers, not all duplications were thought to occur because of an intent to distort data. The types of manipulations identified ranged from unintentional mislabeling to cutting and pasting parts of images, which would be more indicative of an intention to mislead.
The question then becomes, what can be done to identify image manipulations and, ultimately, catch them before they are published? While researchers are actively working to identify duplicated images by eye, others are working to develop software that may be used to catch manipulations before publication. Work by Acuna, et al. 2018 provides a method to detect the duplication of images by comparing images across papers published by the same first or last author. One important limitation of such a method is that it becomes increasingly complex to compare images within a paper to all previously published work; it is why the authors of the method limited the comparisons to works published by the same first or last author. Further, figures can include complex components such as mathematical equations, which may be replicated across publications, or contain objects such as arrows within them that may be duplicated across images. These appropriately duplicated components are mistakenly flagged as image manipulations using the developed software. While these issues present complications when using software that can identify duplication across figures, the authors of this method propose that if journals were to implement the use of such software, that it could deter people from knowingly publishing duplicated images.
In addition to the development of software meant to catch duplications, Fanelli, et al. propose that preventative approaches, such as making and enforcing misconduct policies and promoting research criticism, can help reduce image manipulation in academic research. While this approach rightly aims to change the academic culture that reportedly encourages image manipulation, it will take time for the scientific community to see any effects. In the meantime, what can we be doing to read and think critically of scientific papers, knowing that image manipulation is an existing issue? To keep up to date on the latest in image integrity, and to see what someone with sharp eyes can catch, you can follow Elisabeth Bik on Twitter or look to places such as retraction watch.
References:
- Acuna D. E., P. S. Brookes, and K. P. Kording, 2018 Bioscience-scale automated detection of figure element reuse. Biorxiv 269415. https://doi.org/10.1101/269415
- Bik E. M., A. Casadevall, and F. C. Fang, 2016 The Prevalence of Inappropriate Image Duplication in Biomedical Research Publications. Mbio 7: e00809-16. https://doi.org/10.1128/mbio.00809-16
- Fanelli D., 2009 How Many Scientists Fabricate and Falsify Research? A Systematic Review and Meta-Analysis of Survey Data. Plos One 4: e5738. https://doi.org/10.1371/journal.pone.0005738
- Fanelli D., R. Costas, F. C. Fang, A. Casadevall, and E. M. Bik, 2018 Testing Hypotheses on Risk Factors for Scientific Misconduct via Matched-Control Analysis of Papers Containing Problematic Image Duplications. Science and Engineering Ethics 25: 771–789. https://doi.org/10.1007/s11948-018-0023-7
Additional Articles on Image Duplications:
A recent case of image duplication: https://www.sciencemag.org/news/2019/09/can-you-spot-duplicates-critics-say-these-photos-lionfish-point-fraud